
VERA – Piattaforma AI per la digitalizzazione, trascrizione e catalogazione dei manoscritti
Data product per la gestione e l’arricchimento di manoscritti digitali. Integra immagini, XML e trascrizioni, genera metadati e tag tramite AI e supporta un flusso human-in-the-loop, in cui operatori e revisori verificano e correggono i risultati prima dell’archiviazione.
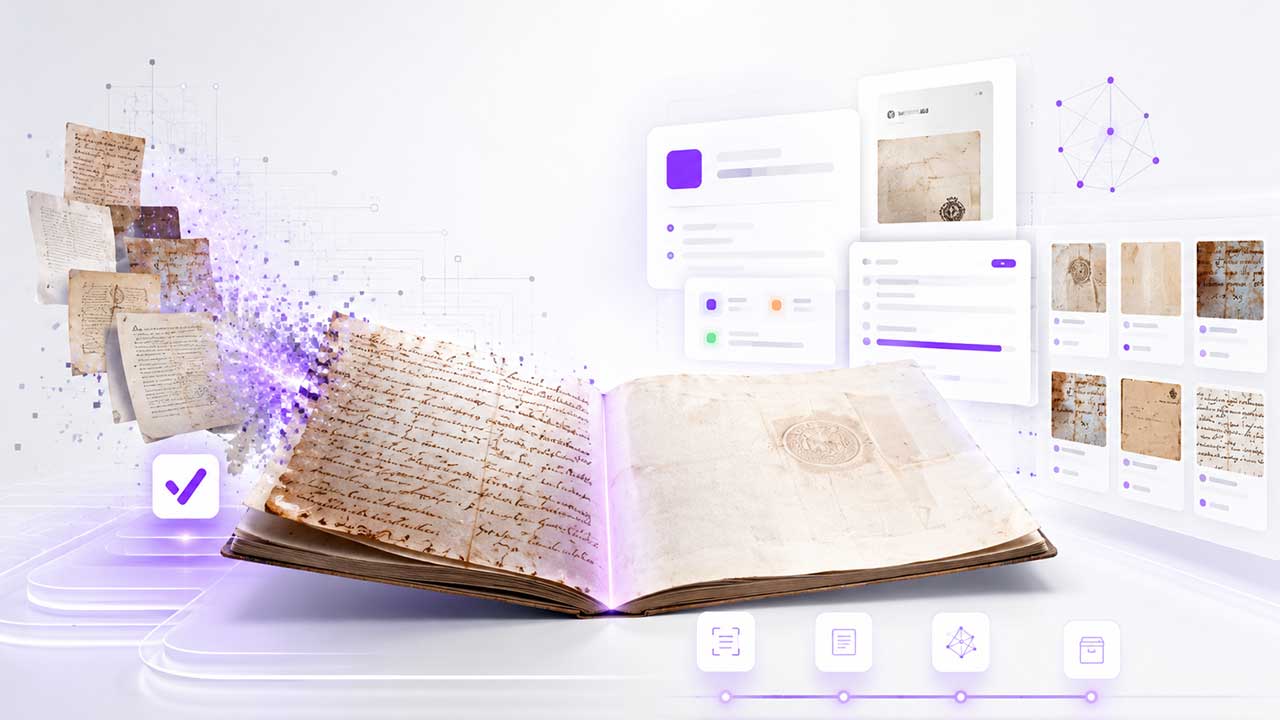
Panoramica
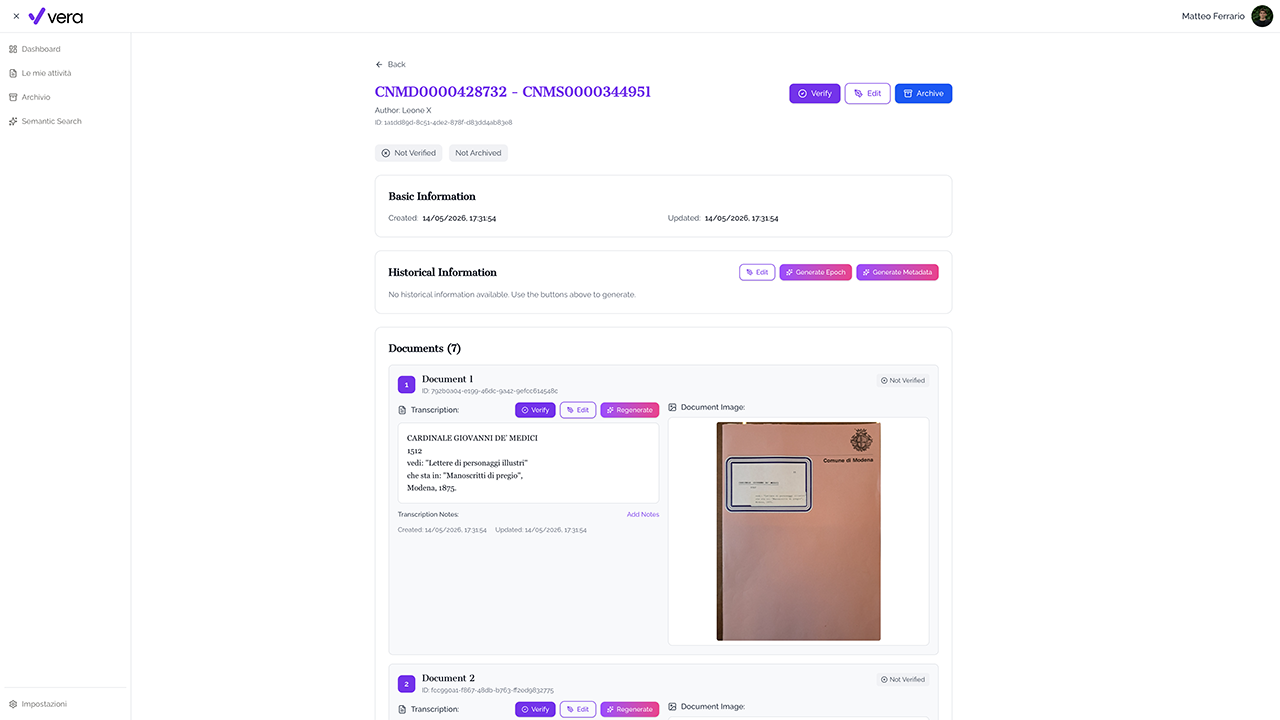
Data Product realizzato nell’ambito dell’evento “Ecomic: Hack the Data Culture”.
Il data product “VERA” propone una piattaforma digitale per la gestione, descrizione e valorizzazione di manoscritti storici. La soluzione integra immagini delle pagine, trascrizioni, metadati descrittivi e strumenti di ricerca, revisione e archiviazione.
Il progetto è stato sviluppato dal team “Malevi”, composto da Matteo Ferrario, Vittorio Napoli e Leonardo Mussato, nell’ambito dell’hackathon “Ecomic: Hack the Data Culture”, svoltosi dal 9 all’11 dicembre 2025 presso il Museo Nazionale Romano – Palazzo Massimo.
La soluzione si è classificata al 1° posto nella Sfida n.1 – “AI per la descrizione del patrimonio culturale”, dedicata allo sviluppo di strumenti intelligenti per automatizzare e migliorare la descrizione dei beni culturali.
La piattaforma comprende l’applicazione web VERA, destinata a operatori e revisori, e un servizio API che gestisce dati, file e modelli AI. L’operatore può creare un manoscritto, aggiungere pagine singolarmente o importarle tramite archivi ZIP contenenti file XML/TEI, immagini ed eventuali trascrizioni.
La soluzione supporta archivi, biblioteche, ricercatori e catalogatori nella gestione dei manoscritti digitalizzati, combinando automazione e controllo umano. Le trascrizioni e i metadati proposti dall’AI possono essere verificati, modificati e confermati prima dell’archiviazione.
Il Data Product utilizza modelli collegati tramite Ollama per trascrivere le pagine ed estrarre informazioni fisiche, codicologiche e storico-descrittive, tra cui materiale, rigatura, legatura, annotazioni, conservazione, epoca, stile e provenienza. L’architettura integra PostgreSQL, Amazon S3, Weaviate, Redis, FusionAuth e Swagger.
Use case principali: analisi linguistica, addestramento di modelli NLP, ricerca archivistica, storica e filologica, digital humanities e percorsi narrativi digitali.
Target: ricercatori, università, sviluppatori AI, enti culturali.
Documentazione
Scopri altri Data Product simili

Clarch Suite – Analisi AI di Manoscritti del Patrimonio Culturale Italiano

Clio – Catalogazione AI di Manoscritti del Patrimonio Culturale Italiano

I dati danno vita alle idee.
Scriviamole insieme
Con DPaaS, puoi trasformare un’idea in una soluzione innovativa concreta, grazie a un laboratorio digitale avanzato che semplifica l’elaborazione dei dati culturali, ne favorisce il riuso e accelera la diffusione di nuovi servizi.